How to eval stateful agents
Most eval setups involve sending a prompt, getting a response, and scoring it. This covers many common tasks, like summarization, classification, extraction, or single-turn Q&A. But it falls apart once your agent starts doing things in unstructured environments over long periods of time.
Statefulness enables an agent to go well beyond the classic prompt-and-response model. With retained memory, impactful action trajectories can be encoded in and expected of agents. A stateful agent creates tickets, updates database rows, sends messages, deploys code, modifies configs, and provisions resources. It builds up context over multiple steps and over long periods of time. It makes decisions that close off some paths and opens others. Its behavior depends on the state of external systems that can change between runs.
You can't eval a stateful agent by replaying a single prompt. You need a different approach that accounts for the different paradigm a stateful agent entails.
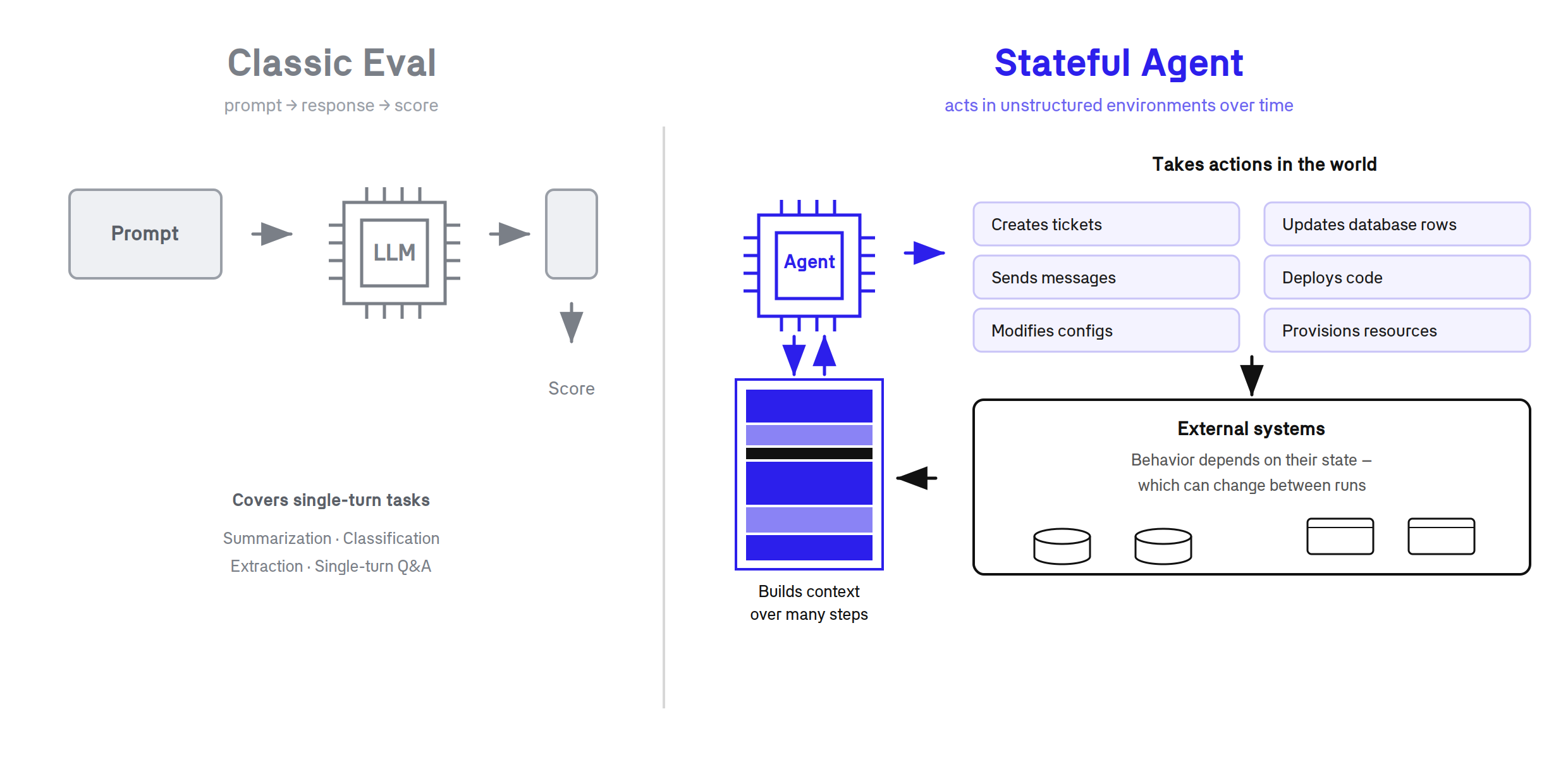
What makes an agent stateful
What does a "stateful agent" mean in practice? It's an agent that accumulates working memory across steps. The agent remembers what it already tried, what the customer said three turns ago, and what intermediate conclusions it reached. Each step builds on the last. The context window is a living workspace that shapes every subsequent decision.
What stateful agents can do
This accumulation and usage of working memory changes what an agent can do, and the downstream impact it can have on your stack.
Stateful agents have side effects. The agent changes the world. It creates tickets, runs database migrations, and sends emails. It doesn't just draft an email, it sends it. A bad decision in a stateless system produces a bad answer, but a bad decision in a stateful system produces bad consequences.
Stateful agents depend on external systems. The agent talks to CRMs, code repos, data warehouses, SaaS APIs, and internal tools. These systems have their own state, and that state changes independently. The same agent running the same task on Monday and Thursday might get different results because the underlying data moved.
Stateful agents are trajectory-sensitive. Early choices change what's possible later. If the agent picks tool A instead of tool B in step two, the entire downstream path shifts. One wrong argument to one API call can cascade through every subsequent step. The order of operations will impact the final output.
An effective stateful eval should be able to manage some combination of these conditions. An agent that builds up context, takes real actions, depends on live systems, and can go down very different paths based on early decisions will not be properly assessed by static prompt-and-response checks.
Why stateful agents are different
The most valuable agents today aren't like the chatbots of earlier models. They're infrastructure agents that create and roll back builds, provision resources, and manage deployments; multi-tool assistants that coordinate across CRM, email, docs, and ticketing systems; or support agents that follow procedures while simultaneously updating records in three different systems.
These agents do real work. That's what makes them valuable, and it's also what makes them harder to eval.
In particular, statefulness introduces several new ways to drift away from the original intent.
Wrong but consistent narrative. If the agent mis-summarizes an early step, later steps build on that summary, so the whole trajectory is self-consistent and wrong in a way that looks "thoughtful."
Mid-context amnesia. Important facts from earlier in a long task may get lost, so an agent completes a slightly different objective than what was actually intended without any obvious error signal.
Stale assumptions. The agent remembers an earlier environment or policy and keeps honoring it after it becomes invalid, so its actions are misaligned with the current world even though they align with history stored in the state data.
State corruption. Concurrent tasks, buggy updates, or bad tools can quietly corrupt memory, leading to contradictions or constraint violations that only show up many steps later.
The failure modes are different from what you see in stateless systems. A stateless agent that gives a bad answer is annoying. A stateful agent that gives a bad answer might also have already executed an irreversible action based on that bad answer.
There are also failure modes that only emerge over multiple steps. A code change that looks fine in isolation could end up breaking something five steps later. A decision that's reasonable given the information at step two may contradict what the agent learns at step six. These regressions don't show up in single-step evals because they require trajectory to surface.
The non-determinism of LLM-based systems surfaces unique implications for stateful agents. Running the same agent on the same task twice might yield different tool call sequences, different intermediate states, or different outcomes because the external systems it depends on returned slightly different data. An eval that isn't built for that variance simply isn't built for stateful agents.
The challenge is state, not scoring
When teams struggle with stateful evals, the instinct is to look for better metrics or fancier scoring systems. That's usually the wrong diagnosis. The hard part is getting the state right.
You need the agent to interact with something real enough to be meaningful so you can properly capture state in your evals. A customer support agent that's supposed to look up orders and issue refunds needs an actual order database to look things up in and an actual refund system to issue refunds through. A deployment agent needs something to deploy to. An infrastructure agent needs infrastructure.
But "real enough to be meaningful" and "fully realistic production environment" are very different, and finding the right balance between them can cost teams both time and money.
Building a perfect replica of your production environment for eval purposes is expensive to set up and difficult to maintain. Every time the real environment changes, your eval environment needs to change too. Teams that try this method often spend more time maintaining their eval infrastructure than actually improving their agents.
The practical approach is to be deliberate about what needs to be real and what can be mocked.
Make state explicit. Before building anything, write down which parts of the environment the agent actually interacts with and which of those interactions need to be realistic for the eval to be meaningful.
Make the environment resettable. When you do need real state, make sure you can reset it between runs. If every eval run leaves behind artifacts that affect the next run, your results become unreliable fast.
Don't chase perfect replay. Trajectory variance rises alongside tool depth. An agent that makes two tool calls has a manageable number of possible paths, but an agent that makes fifteen tool calls has a combinatorial explosion of paths. Focus on outcomes and key decision points instead of trying to reproduce exact sequences.
The stateful eval lifecycle: observe, capture, test, iterate
The most productive pattern for stateful evals is to start with production, build test cases from real failures, score the agent's path and outcome, then implement evals programmatically in future CI/CD workflows. Once you've gone through this process and have established evals as part of your team's development lifecycle, you'll be able to iterate faster and more effectively.
Step 1: Observe what happens in real runs
Log traces, tool calls, inputs, outputs, metadata, and intermediate state. When the agent creates a ticket, log what it created. When it makes an API call, log the arguments and the response. When it updates a record, log the before and after.
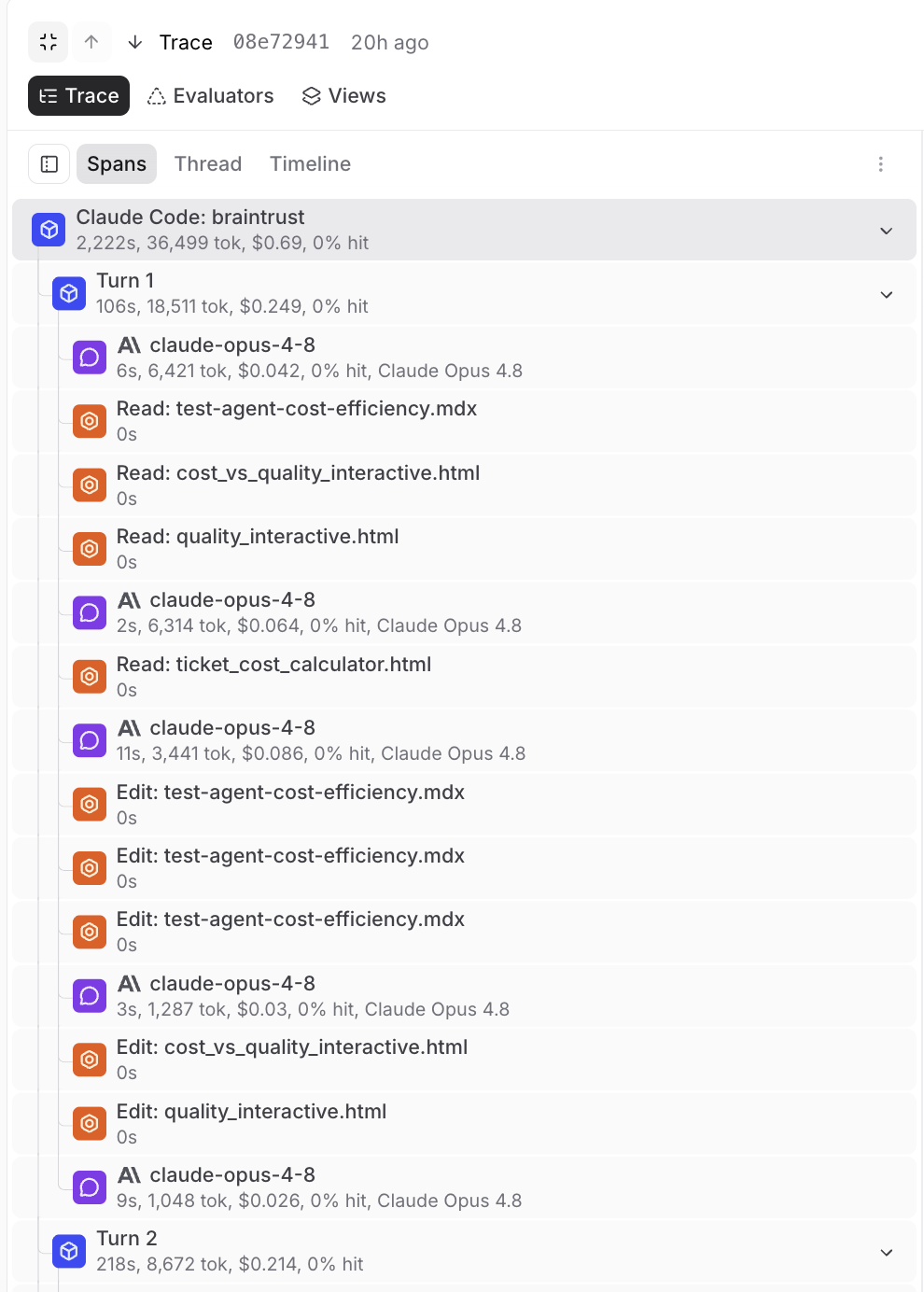
Braintrust makes it easy to instrument your agent. The SDK wraps common providers, so every LLM call, tool invocation, and application-layer interaction gets captured as a structured span. The @traced decorator (Python) or wrapTraced() (TypeScript) handles nesting, so multi-step agent runs produce a trace tree that shows the full execution path. Each span records token counts, latency, time to first token, and estimated cost automatically.
The trace view in the Braintrust UI lets you walk through the full execution graph. You can switch between a tree view for seeing the span hierarchy, a timeline view for spotting latency bottlenecks, and a thread view for reading the conversation as a continuous exchange. For stateful agents, the tree view is usually the most useful because it shows you the decision structure and not just the conversation.
You can filter and search across your logs using SQL-style expressions against input, output, metadata, scores, or any field you've logged. With Topics, Braintrust will automatically surface the patterns of agent behavior that are most likely to be relevant. For a high-volume agent, this is often the best way to find the specific set of traces where the agent failed. For example, you could filter to see all spans where metadata tags indicate that information had already been pulled from the CRM at a previous step, and compare those against spans where it had not, revealing whether redundant CRM calls are introducing latency, degrading output quality downstream, or whether the pipeline is simply ignoring state it already has.
Step 2: Turn failures into test cases
When something goes wrong in production, instrumentation allows you to capture that specific scenario. Take that information, and turn it into a regression test. This is worth more than synthetic test cases because it represents a failure mode that occurred with a real customer.
Braintrust has a few ways to do this. The simplest is to browse your logs, find a bad trace, and promote it directly into a dataset. Select the trace or a specific span within it, select Add to dataset, and it becomes a row in a versioned dataset that you can use in future eval runs. You can do this from the UI or from the bt CLI.
For bulk operations, dataset pipelines automate the process. You define a pipeline in code with a source, a transform function, and a target dataset. Run it with bt datasets pipeline run and it pulls matching traces, transforms them into dataset rows, and writes them to your target dataset. You can filter by metadata flags, score thresholds, error status, or any other field. For example, when working on an IT access application, you could build a pipeline that automatically pulls every trace where the brand alignment score was below 50% and turns it into a test case:
DatasetPipeline({
source: {
projectName: "IT Access Agent",
filter: "scores.brand_alignment < 0.5",
scope: "trace",
},
transform: ({ trace }) => ({
input: trace.input,
expected: trace.metadata?.expected_outcome,
metadata: { original_score: trace.scores?.brand_alignment },
}),
target: {
projectName: "IT Access Agent",
datasetName: "Low-quality cases",
},
});
The staged workflow (pull, transform, push) lets you inspect and edit the transformed rows before committing them, which is useful when you need a human to review whether a trace is actually a failure worth codifying.
Over time, your dataset grows from production data, reflecting the actual failure modes of your specific agent in your specific environment.
Step 3: Score the steps and the outcome
Stateful agents need scoring at two levels. Single-step scoring checks whether individual decisions were correct, while end-to-end scoring checks whether the overall task succeeded.
Braintrust supports both. For single-step scoring, you can attach scorers at the span level. An LLM-as-a-judge scorer can eval whether each tool call was appropriate given the context. A code-based scorer can check structured outputs, like whether the SQL query matches the expected schema, whether the API call used the right endpoint, or whether the response parses correctly.
For end-to-end scoring, trace-scoped scorers eval the full execution. A trace-level scorer gets access to the entire conversation thread via trace.getThread() and all spans via trace.getSpans(). It can check whether the agent's task was completed, whether it took a reasonable path to get there, and whether it left the environment in the right state.
You can hook intermediate results into your scorers using the hooks argument in your eval's task function. If an agent does tool calls, attach them to metadata so your scorers can eval the specific tools chosen and the arguments passed. This is how you catch the case where an agent arrives at the right answer through the wrong path, which, for a stateful agent with potential side effects, matters as much as the answer itself.
Both levels of scoring work in online mode. Configure online scoring rules under Automations in the Braintrust UI, set a sampling rate based on your traffic, and scores show up in your logs attached to the relevant span or trace, along with the judge's reasoning if you're using LLM-as-a-judge.
Step 4: Run evals before shipping
Once you have a dataset of real failure cases and a set of scorers, wire them into your CI pipeline. Braintrust has a GitHub Action that runs your eval suite on every pull request and posts the results directly in the PR. It compares scores against your production baseline and shows deltas, like which test cases improved, which regressed, and by how much. If a quality threshold isn't met, the merge is blocked.
This is how to turn a production failure into a test case that gets scored automatically on every code change. If someone introduces a regression that would cause a previously captured failure, CI catches it before it ships. For example, changing the communication from the agent's state memory store in a way that increases verbosity could silently push the model over its context window, degrade instruction-following, or cause downstream spans to misread structured data they were expecting in a tighter format.
Step 5: Iterate
Fix the issue, re-run the test case, verify it passes, and check that nothing else broke. Add the test case to your permanent suite.
This process, once implemented programmatically, compounds over time. Each cycle makes your eval suite more representative and your agent more robust.
What this looks like in practice
Consider an example agent that handles internal IT requests. An employee submits "I need access to the analytics dashboard" to the agent, which is supposed to check who the requester is, verify they're authorized, create the access grant in the identity provider, and confirm completion with the requester.
A stateless eval would test whether the agent generates a reasonable-sounding response to that request. A stateful eval verifies the full chain of agent behavior: did it look up the right person, did it check the right authorization policy, did it create the access grant with the correct permissions, did it create it in the right system, and did it confirm accurately? Did the overall trajectory make sense, not overly repeat itself, and not take harmful actions on its way to the correct action?
Each of those steps depends on state. The lookup depends on the identity provider's data. The authorization check depends on the policy engine's current rules. The access grant depends on the identity provider accepting the write. If any of those systems behave differently than expected, the agent might fail in ways that a static eval would never catch.
In Braintrust, you'd instrument the agent so each step logs as a separate span in the trace. Span-scoped online scoring checks each step individually, and a trace-scoped scorer evals the outcome.
When the agent fails, you find that trace in your logs, filter by the error pattern, and promote it to a dataset. Your transform function captures the requester, the policy state at the time, and the API response. You fix the parsing logic, run your eval suite, verify the test case passes, and the GitHub Action blocks any future change that would reintroduce the bug.
Finding patterns at scale
Individual trace reviews are useful for debugging specific failures, but they don't scale. If your agent handles thousands of requests a day, you need aggregate patterns.
Braintrust's Topics feature generates a natural-language summary of each trace, then clusters those summaries into buckets based on the critical patterns that emerge from your agent's behavior.
Each trace gets labeled with its cluster. You can see distributions, drill into the most pressing clusters, check the scores, and identify a specific category of failure worth investigating. It turns a wall of trace logs into a prioritized list of problems, ranked by frequency and severity. When dealing with stateful agents, automation like this can make the overall eval process easier to manage as complexity grows.
The most important agents do important work
Stateful agent evals are fundamentally a different category of AI infrastructure. State management adds new complexity, like setting up environments that are realistic enough to be useful, resettable enough to be reliable, and cheap enough to maintain.
Start with observability. Instrument your agent so every step logs as a structured span. When things break, find those traces, promote them to datasets, and build scorers that check both individual steps and overall outcomes. Wire the whole thing into CI so regressions get caught before they ship. Use online scoring and clustering to monitor production and surface new failure patterns as they emerge.
Stateful agents that do real work are worth investing in, and they're also harder to eval. The gap between those two facts is where your eval infrastructure needs to grow and change. Get started with Braintrust to build evals for the agents that matter.